Many applications will fetch content from a third-party resource, sometimes controlled by a user. For example, WebHooks provide the ability for an application to reach out to a URL given by a user to inform them of a completed action. As this resource is not controlled by the application it can be dangerous to trust blindly. This is where the Server-Side Request Forgery (SSRF) vulnerability comes in.
Given the following code example, you may be able to spot exactly what the vulnerability here is:
<?php
// Get the URL from the user
$url = $_GET['url'];
$response = file_get_contents($url);
echo $response;
?>As you can see, the user is providing a “url” parameter that gets processed by the application as it fetches the contents of the URL. With this example there are actually a couple of vulnerabilities. To name a couple, and we will be leaving out the rest for this article as they aren’t relevant, we have a Server-Side Request Forgery, aka SSRF, vulnerability as well as an Arbitrary File Read/Path Traversal vulnerability, but for this post we will concentrate on the SSRF vulnerability.
Server-Side Request Forgery (SSRF)
Let’s first address the SSRF vulnerability. Let’s say that the user provides a URL such as https://hubblesec.com. The application will fetch the contents of the HubbleSec homepage and echo it out in the response. This is a fairly innocuous example, but let’s say the user gives the URL of https://192.168.0.1/. This means the application would fetch the contents of the internal network’s router’s page. This could lead to other vulnerabilities like authorization bypass or information disclosure as the page may not require authentication or may contain some sensitive information like server addresses, users, or even passwords. It is possible for an SSRF to be leveraged to take over an entire AWS, Google Cloud, Digital Ocean, Azure, etc, estate. This is done by using the meta-data URLs, such as http://169.254.169.254 which can disclose private SSH keys and other very sensitive data.
Depending on what further attacks can be performed, for example, the aforementioned authorization bypass or information disclosure, the Server-Side Request Forgery would often be categorized as a High to Critical risk vulnerability.
How To Prevent SSRF?
You may be thinking to yourself, “Well, if this is such a critical vulnerability, how do I prevent it?”
What we know:
- The user gives a URL parameter (By any method – GET, POST, PUT, PATCH, DELETE, Cookies etc)
- No validation is done on the URL
- The application fetches the contents from this URL
- Something happens to the contents of the response
Let’s look at the problem from the bottom up and see what we can do to prevent it.
“Something happens to the contents of the response” – Your first thoughts here may be that you could just prevent the response from the URL being rendered or printed anywhere, but this would only result in, what is known as a Blind SSRF attack. This happens when you remove the contents of the response from the equation but the attacker would still be able to see the incoming request in their logs on their server. For example, the following screenshot shows the incoming HTTP requests to a server that they control:
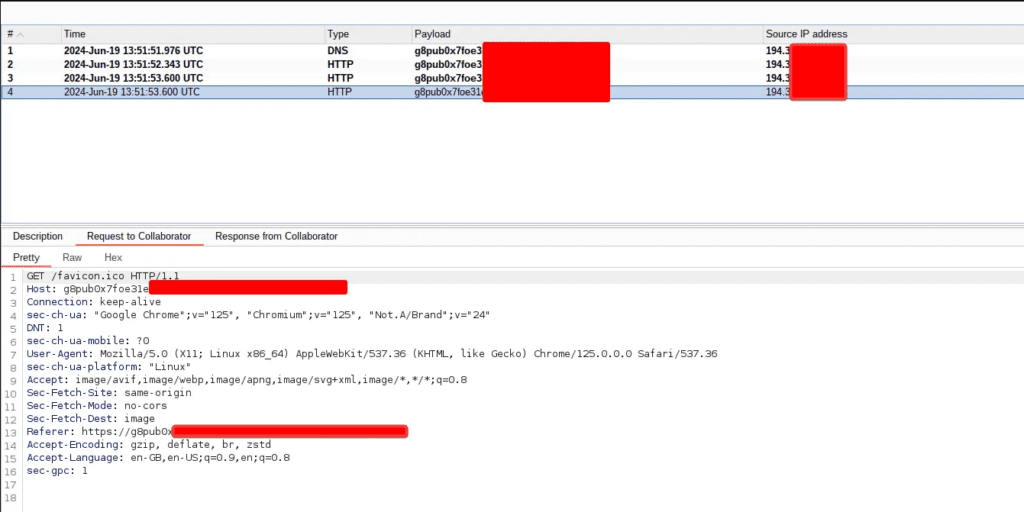
So even if you don’t render the response, they will be able to see that your application is processing the URL and fetching it.
There is also another issue to think about here and that is timings. If the attacker can provide a URL that they know will fail, something that, for example, doesn’t have a DNS record, then the chances are the application will be quick to respond with a failure message. However, if the attacker provides an internal network URL (https://192.168.0.1) they may be able to test the response times to verify whether or not it is being fetched successfully. One solution here may be to add a random sleep timer within the code to prevent timing attacks or send the fetching process off to another system to run asynchronously.
“The application fetches the contents from this URL” – Depending on the type of application or function you are trying to implement, this may be a requirement, but it should be done safely and securely. To do this safely, several things should be considered, for example:
- Are there specific reasons for what you are implementing, such as a webhook?
- Do you need the contents of the remote resource back or do you just need to send a request?
- Do you trust the remote system?
- Is there a way that you can verify the remote resource is safe and the intended target?
For resources like webhooks there usually aren’t any good reasons to fetch the response from the server, so for that reason you don’t need to output anything to the user’s page.
If you don’t trust the remote system, by that we mean, any system that is provided by a user and not under your control, then you may want to enforce some form of verification process. This could be a specific file on the remote server that your application can check for first to ensure that the remote server has been set up and verified for this action. Think of this as a DNS record validation using TXT entries. But again, think about timings and other potential attack vectors here.
“No validation is done on the URL” – If your application needs to perform a cURL request (or similar) and you know exactly where the request should be going then make sure that this is not provided by the user. This can be hardcoded or if a dynamic value is required, always make sure that it is first validated and has not been tampered with.
For this we can take a look at the following example:
<?php
// Get the region from the user
$region = $_GET['region'];
$url = sprintf('%s.trustedsite.com', $region);
// Make the request
$response = file_get_contents($url);
echo $response;
?>In this example, we see that the region is prepended to the URL, but the problem with this is that there is no validation on the parameter and an attacker may be able to use a payload like:
evil.com/#Which would result in the final URL looking like this:
evil.com/#.trustedsite.comThis would end up hitting the evil.com site’s homepage with the #trustedsite anchor link.
So, you may now be wondering, what if I give a set of URLs that are in an allow-list. This would be a great solution depending on the implementation. If we take a look at the code below, we will see that only two URLs are trusted and the attacker would have to find a way to bypass these checks if they wanted to exploit the vulnerability:
<?php
// Get the URL from the user
$url = $_GET['url'];
$ip = gethostbyname($url);
// Check if the URL is in the allowed list
$allowed_ips = array("127.0.0.1", "192.168.0.1");
if (in_array($ip, $allowed_ips)) {
// Make the request
$response = file_get_contents($url);
echo $response;
} else {
echo "URL not allowed";
}
?>Can you see it? There is another vulnerability here, and it is known as the Time Of Check Time Of Use (TOCTOU) attack. In this example, the $allowed_ips may be a list of URLs previously agreed upon for the user to access. The attacker provides a URL that matches one of the $allowed_ips entries, then the request will be made. But, the system checks for the value before the system makes the call which gives the attacker time to change the host to which the DNS entry points. This is known as a DNS rebinding attack. To prevent this, you must validate the host and then use the result as part of the lookup. This way the attacker has no chance to perform a rebinding attack.
The patch involves resolving the IP address of the URL before checking it against the allowed list and then using the resolved IP address when making the request.
<?php
// Get the URL from the user
$url = $_GET['url'];
// Resolve the IP address of the URL
$ip = gethostbyname(parse_url($url, PHP_URL_HOST));
// Check if the IP is in the allowed list
$allowed_ips = array("127.0.0.1", "192.168.0.1");
if (in_array($ip, $allowed_ips)) {
// Make the request using the resolved IP
$response = file_get_contents($ip);
echo $response;
} else {
echo "URL not allowed";
}
?>“The user gives a URL parameter (By any method – GET, POST, PUT, PATCH, DELETE, Cookies etc)” – Finally, the user provided the input. If this is not required then the best course of action is to hardcode any URLs you want to fetch content from and only trust those URLs.
The Elephant In The Room
So for you keen-eyed readers, you may have realised that we only spoke about the HTTP protocol and not reading local files using file:// or performing other binary protocol attacks. That is because this post was only intended to cover the HTTP protocols and in another future blog post we will write about other protocols and the Arbitrary File Read attacks related to this code.